

Wie du die Aufnahme deiner Webseiten in Suchindex mittels robotx.txt richtig steuerst und das Ranking der Website positiv beeinflussen kannst
Anfang Juli 2019 gab Google die Meldung raus, dass der Tag <noindex> in der robots.txt nicht mehr unterstützt wird und fordert nun auch über die Google Search Console in einer Mail auf, diesen Eintrag zu entfernen.
Aber selbst wenn du keine Mail erhalten hast, findest du hier Tipps, wie du dein Ranking durch geschickte Steuerung des Crawling verbessern kannst. Für diejenigen, die die Mail von Google erhalten haben, aber gar nicht wissen, wie sie vorgehen sollen, gibt es ebenfalls ein paar konkrete Tipps zur Vorgehensweise.
1. Was ist die robots.txt?
Die robots.txt ist eine Textdatei, die im Stammverzeichnis der Website auf dem Server liegt. Sie enthält Anweisungen auf welche Verzeichnisse oder Dateien die Crawler der Suchmaschinen zugreifen dürfen und auf welche nicht. Sie dient also der Steuerung des Crawlingverhaltens.
Du brauchst eine solche Datei nicht unbedingt, wenn die Crawler auf alle Seiten, Bilder oder PDFs zugreifen dürfen oder du einzelne Seiten bereits per noindex-Tag ausgeschlossen hast. Wie das in WordPress funktioniert, erfährst du weiter unten. Grundsätzlich gehen die Crawler nämlich davon aus, dass sie alles auf einer Website sehen dürfen. Warum es aber oft nicht sinnvoll ist, den Crawlern alles anzubieten, erfährst du beim nächsten Punkt.
2. Was bewirkt der noindex-Tag und warum ist er wichtig?
Grundsätzlich steuert man mit dem diesem Tag die Blockierung der Aufnahme einer einzelnen Webseite in den Suchindex von Google. Ist im HTML-Code der Seite der Tag vorhanden, erkennt der Googlebot beim nächsten Crawlen, dass diese Seite aus den Suchergebnissen ausgeschlossen werden soll. Auch andere Suchmaschinen unterstützen diesen Tag.
Es ist generell wichtig sich genau zu überlegen, ob die Sichtbarkeit bestimmter Seiten beschränkt werden soll, die weniger wertvoll sind. Denn wenn es zu viele Seiten gibt, die wenig Mehrwert für Nutzer haben, kann sich das negativ auf das Ranking auswirken.
Beispiele für wenig wertvolle Inhalte sind z.B. duplizierte Inhalte durch die Suchfunktion, durch Kategorien und Verschlagwortung oder durch Filteroptionen. Alle diese Möglichkeiten generieren immer wieder neue URLs, die Google crawlen müsste. Solche URLs, die gerade bei Filtern in die Tausende gehen können, sind aber letztendlich vom Inhalt her immer gleich. Jede Website verfügt über ein bestimmtes „Crawl-Budget“ und wenn Google viele ähnliche Seiten sieht, werden möglicherweise nicht die richtigen Seiten von Google indexiert und das Ranking in der Google-Suche verschlechtert sich.
3. Warum unterstützt Google diesen Tag in der robots.txt nicht mehr?
Noindex in der robots.txt unterzubringen, war noch nie die richtige Vorgehensweise, v.a. wenn zusätzlich auch die Seite im HTML-Code den <noindex>-Tag enthält. Denn der Crawler sieht die Anweisung <noindex> dort nicht, wenn er durch die robots.txt angehalten ist, die Seite nicht in den Index zu bringen. So kann sie trotzdem in den Suchergebnissen erscheinen. Das passiert dann, wenn es z.B. Verlinkungen zu den auf <noindex> gesetzten Seiten gibt.
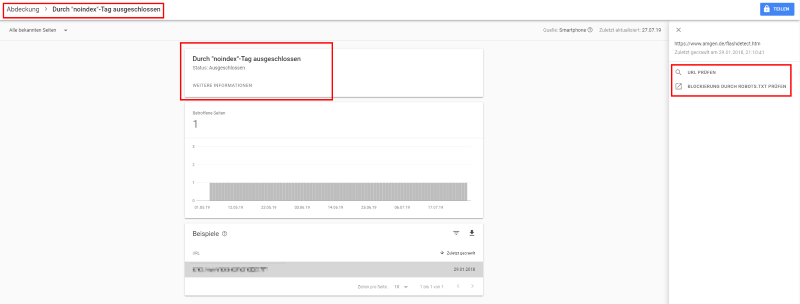
In der Search Console findest du Hinweise, wenn es hier unbeabsichtigt Fehler gibt, z.B. Indexiert, obwohl durch robots.txt blockiert

4. Wo sehe ich, was in der robots.txt eingetragen ist?
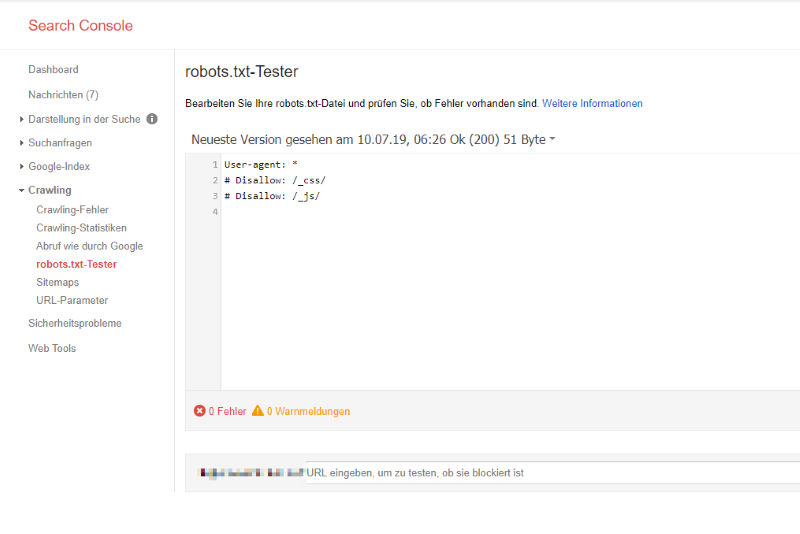
In der Google Search Console findest du das robots.txt Test-Tool, das momentan noch zur alten Search Console führt. Gehe dazu im Menü auf Abdeckung, wähle eine Seite aus und klicke darauf. Dann findest du rechts den Link zum robots.txt-Testtool:
5. Wo kann ich in WordPress eine Seite oder die ganze Website auf noindex setzen?
Wenn eine WordPress-Website noch im Aufbau ist und noch nicht in den Suchmaschinen sichtbar sein soll, kann dies in den WordPress Einstellungen geregelt werden. Allerdings war es bisher so, dass mit dem Setzen des Hakens in der robots.txt der Eintrag „Disallow: /“ erschien. Diese Einstellung findest du unter „Einstellungen – Lesen“:

Das ist allerdings keine sichere Methode, denn auf diese Weise gesperrte Seiten können trotzdem in den Suchergebnissen erscheinen. Mit der WordPress Version 5.3. allerdings wird das Meta-Robots-Tag „noindex, nofollow“ gesetzt werden, was sicherer ist (https://make.wordpress.org/core/2019/09/02/changes-to-prevent-search-engines-indexing-sites/)
Wenn du in WordPress nur eine einzelne Seite von der Indexierung ausschließen möchtest, ist es am einfachsten, wenn du ein SEO-Plugin wie z.B. Yoast oder All-in-One-SEO verwendest. In Yoast kannst du die Seite in den Einstellungen, die sich jeweils im SEO-Block unter der Seite oder dem Beitrag befinden, ausschließen:
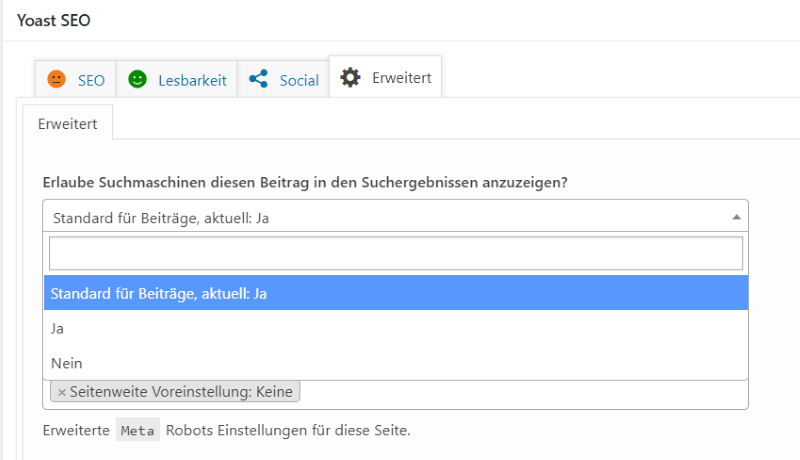
Auch ganze Verzeichnisse kannst du mit dem Plugin ausschließen, vor allem wenn du einen Blog mit sehr vielen Kategorien und Schlagworten hast, die immer wieder neue URLs generieren. Auch Feeds, Suchergebnis-Seiten und die Attachment-URLs etc. können ausgeschlossen werden.
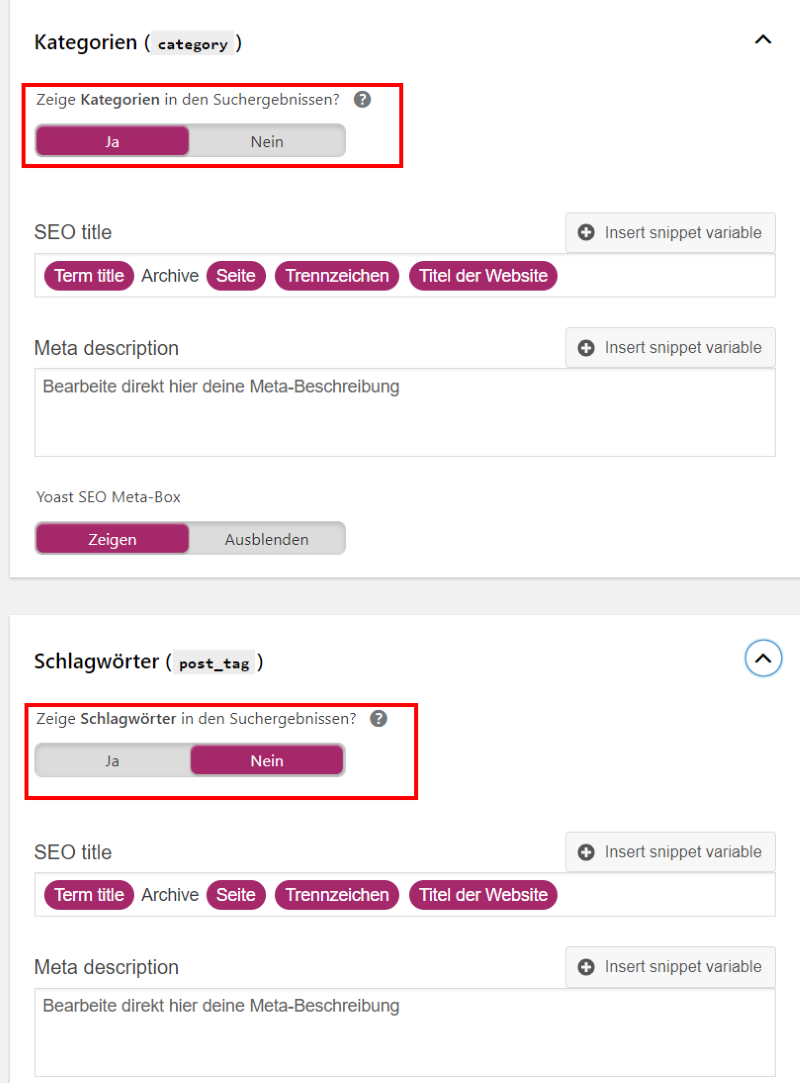
Es ist auch möglich mit dem Plugin die robots.txt zu bearbeiten, was ziemlich cool ist:

Hier findest du mehr zum Thema WordPress-SEO mit dem SEO-Plugin von Yoast.
In der Google Search Console siehst du dann unter Abdeckung welche Seiten gültig und welche ausgeschlossen sind. Hier in diesem Beispiel werden ca. 6 mal mehr Seiten ausgeschlossen als gültig sind. So gibt man Google klare Signal, was wichtig und was unwichtig ist.
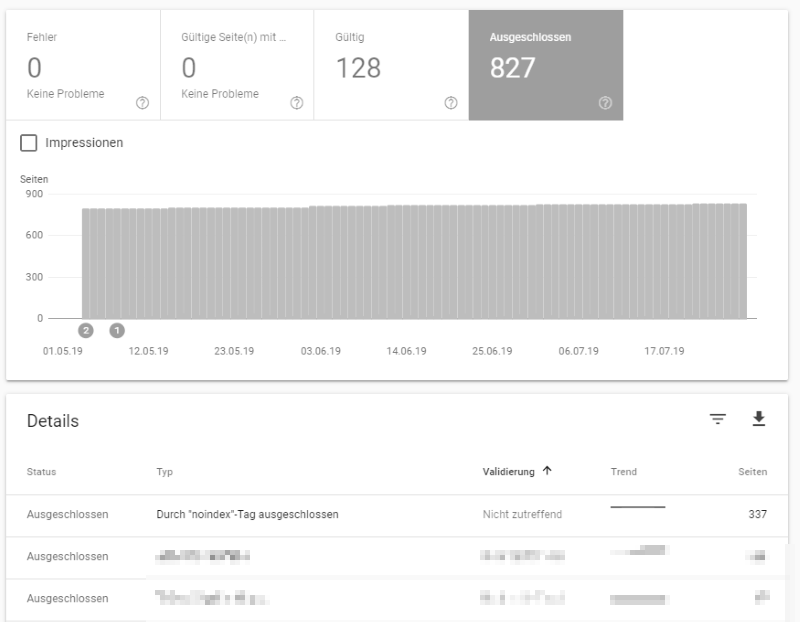
Natürlich lohnt es sich, mal ab und an zu schauen, ob bei den ausgeschlossenen Seiten alles seine Richtigkeit hat.
6. Woher weiß ich welche Seiten meiner Website indexiert werden?
Du kannst mit dem Befehl site:https://example.de in der Google-Suche alle Dateien auflisten, die Google findet.
Auf einem amerikanischen SEO-Blog habe ich gelesen, dass dies auch eine Einordnung der Wichtigkeit der Seiten sei. Das kann ich mir gut vorstellen, aber man darf dies nicht mit dem Ranking verwechseln, denn die Position in den Suchergebnis ist ja immer abhängig von dem Suchbegriff, den der Nutzer gewählt hat.
7. Meine Seite wird immer noch gefunden, was soll ich tun?
Wenn die Seite weiterhin in den Suchergebnissen erscheint, wurde seit dem Hinzufügen des noindex-Tags die Seite schlichtweg noch nicht wieder vom Crawler besucht. Hier heißt es in jedem Fall Geduld haben. Das Crawling und auch die Indexierung sind laut Google „komplizierte Prozesse, die bei bestimmten URLs manchmal recht lange dauern können“. Dies ist gerade auch der Fall, wenn deine Website eher klein ist und wenig neue Inhalte erscheinen.
In der Search Console kannst du die URL prüfen lassen und zwar an der gleichen Stelle wie in obigem Screenshot (URL-Prüfung). Auf diese Weise beantragst du das erneute Crawlen der Seite. Die Crawler kommen schließlich nicht ständig auf deiner Website vorbei, vor allem dann nicht, wenn sich praktisch nichts tut, d.h. es keine neuen Inhalte gibt.
Gleichzeitig prüfst du natürlich, ob der noindex-Tag wirklich aus der robots.txt entfernt wurde, wie weiter oben beschrieben.
8. Was soll ich auf keinen Fall tun, wenn die Seite immer noch im Index ist?
Wenn eine Seite bereits gelöscht wurde, weil sie ganz und gar nicht mehr passt, ist es natürlich ärgerlich, wenn sie immer noch im Index erscheint. Was du aber in keinem Fall tun solltest, ist der Ausschluss einer bereits auf noindex stehenden Seite mit dem Befehl „Disallow“ in der robots.txt. Hier gilt das Gleiche wie mit dem noindex, der Crawler sieht, dass er die Seite nicht crawlen darf, erkennt den noindex auf der Seite selbst aber nicht. So kann die Seite potenziell immer noch im Suchindex bleiben.
Übrigens garantiert der Disallow-Befehl nicht, dass eine Seite in den Suchergebnissen erscheint. Wenn die Seite als relevant eingestuft wird, weil sie eingehende Links enthält, kann sie trotzdem indexiert werden.
Außerdem – und das ist ganz wichtig – dürfen css und Javascript-Dateien nicht ausgeschlossen werden, da Google sonst die Seiten nicht richtig rendern kann. Du solltest dann aber auch (wenn du die Search Console hast) eine Mail bekommen haben, dass der Googlebot auf diese Dateien nicht zugreifen kann.
Natürlich darfst du die robots.txt nicht für private Inhalte verwenden. Diese kannst du mit einem Passwort schützen über eine serverseitige Authentifizierung.
Hier findest du übrigens eine Liste aller Regeln für die robots.txt: https://developers.google.com/search/reference/robots_txt
9. Die robots.txt und die XML-Sitemap
Es ist empfehlenswert in der robotx.txt auf die XML-Sitemap zu verlinken, z.B.
Sitemap: https://example/sitemap.xml
In der Search Console kannst du die Sitemap einreichen. Auch hier achtest du darauf, dass nicht alle Seiten mittels Sitemap eingereicht werden, v.a. natürlich nicht die auf noindex gesetzten Seiten oder Seiten ohne Mehrwert wie weiter oben bereits beschrieben.
10. Fazit
Die Steuerung des Crawling durch die Googlebots mit Hilfe der robots.txt ist eine wichtige Sache, wenn Seiten oder Verzeichnisse ausgeschlossen werden sollen. Welche Vorgehensweise hierbei richtig ist, musst du dir genau überlegen bzw. mit deinem Webprogrammierer besprechen. Letztendlich trägt der richtige Umgang damit viel zur Sichtbarkeit deiner Website bei.
Das volle Optimierungspotential für ein besseres Ranking der Website
Jetzt mit einem SEO-Audit das volle Optimierungspotenzial kennenlernen und so die Basis für die richtige SEO- und Contentstrategie schaffen.